Problems LLMs (Currently) Have: Navigating Limitations in Legal AI

Adult supervision required
Legal professionals need a clear-eyed view of where LLMs struggle so they can navigate the pitfalls that come from misplaced confidence.
Below I’ll go over some limitations in the current generation of models that I consider most impactful in legal contexts, and strategies I’ve found helpful in managing them day-to-day.
Takeaways

Sycophancy:
LLMs often agree with users by default, even when incorrect.
Mitigate this through:
neutral prompt framing
explicit instructions to challenge assumptions
structured context

Needle in a haystack:
LLMs can miss specific information in long contexts or prompts.
Address this by:
dividing any task that would require more than 20 pages of input into smaller steps
distilling key information into structured context
directing the model's attention to specific sections
implementing orchestrated workflows
Multi-task processing:
LLMs can do many kinds of things, but they perform much better when doing one kind of thing at a time.
Break complex tasks into discrete steps with specialized prompts and targeted context for each stage.
Work toward implementing orchestrated workflows.

Formulaic output:
LLMs often produce text that is overly polished and prone to repetitive phrasing, sometimes derisively called “AI slop”.
Provide a stylebook with voice, tone, and formatting guidelines to get better first drafts
Human refinement as needed (and it will be needed)
These limitations reflect the state of LLM technology as of this writing.
Longer-term developments in knowledge representation, new model architectures, and multi-agent orchestration may reduce or even entirely eliminate many of these issues. Until then, thoughtful implementation and human oversight remain essential.
"Leading the Witness": LLM Sycophancy
LLMs are designed to be helpful, which often translates to agreeing with you even when you're wrong. Out of the box, these models have a strong tendency to accept flawed premises rather than challenge them.
This happens (in part) when models are trained through reinforcement learning with human feedback (RLHF), a process which incentivizes them to prioritize agreeability over truthfulness.
RLHF “rewards” models for responses humans rate as helpful, which may or may not have a relationship to reality.
So when you ask “Can you find me a contract we’ve signed with this counterparty that supports X position?”, an LLM interprets this as a request to produce something helpful, not necessarily something real.
It’s something like an overly eager student who fabricates a test answer rather than leaving it blank or writing “I don’t know”.
The fabricated information often sounds plausible and may align perfectly with what you hoped to find (not surprising, since the AI invented it specifically to meet your needs). The model may also fail to identify conflicting information or alternative points of view.
But fear not, dear reader. That very same agreeability means most LLMs will readily adopt a role the user gives them, and they love to follow instructions to the best of their ability, which means we can shift the LLM away from its default people-pleasing behavior:
Explicitly instruct the model to challenge assumptions, flag uncertainties, and consider alternatives
Provide structured context to ground the LLM's responses, rather than relying on the model's internal knowledge:
the role the LLM has
how it should perform the task
your situation and overall objectives
the next step you’ll take with the output
Frame questions neutrally to avoid leading the AI:
For example, ask “What contracts address this issue?” rather than “Find language supporting my position”
Have humans in the loop to verify factual claims
Needle in a Haystack: Context Window Limitations
If you’ve ever written an inordinately long stream-of-consciousness email or text message novella about something Very Important and received a response that didn’t seem terribly concerned about the subject matter but very concerned about placating you, that’s essentially plays out when you ask an out-of-the-box LLM to execute a very long, disorganized prompt.
If you’ve ever heard a person talk at length about a book they didn’t read, that’s essentially plays out when you ask an out-of-the-box LLM to analyze a very long contract.
Despite marketing claims about massive context windows, research consistently shows these models struggle to utilize information in long contexts effectively.
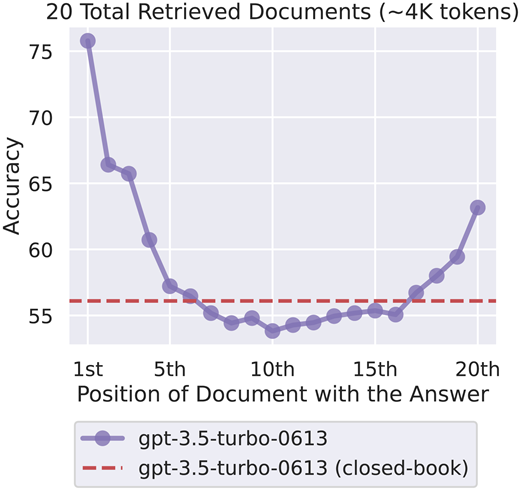
When models are asked to retrieve specific information (the “needle in a haystack”) from long context, research finds a “Lost in the Middle” effect.
This U-shaped performance curve shows that LLMs perform better when the “needle” is at the beginning or end of the input, but struggle when it’s in the middle.
This happens because their attention mechanisms have both primacy and recency bias (position matters).
Figure: Accuracy of language model in retrieving relevant documents by position of the target document. Source: Liu et al. (2024). "Lost in the Middle: How Language Models Use Long Contexts." Transactions of the Association for Computational Linguistics, 12, 157–173. Available at https://doi.org/10.1162/tacl_a_00638.
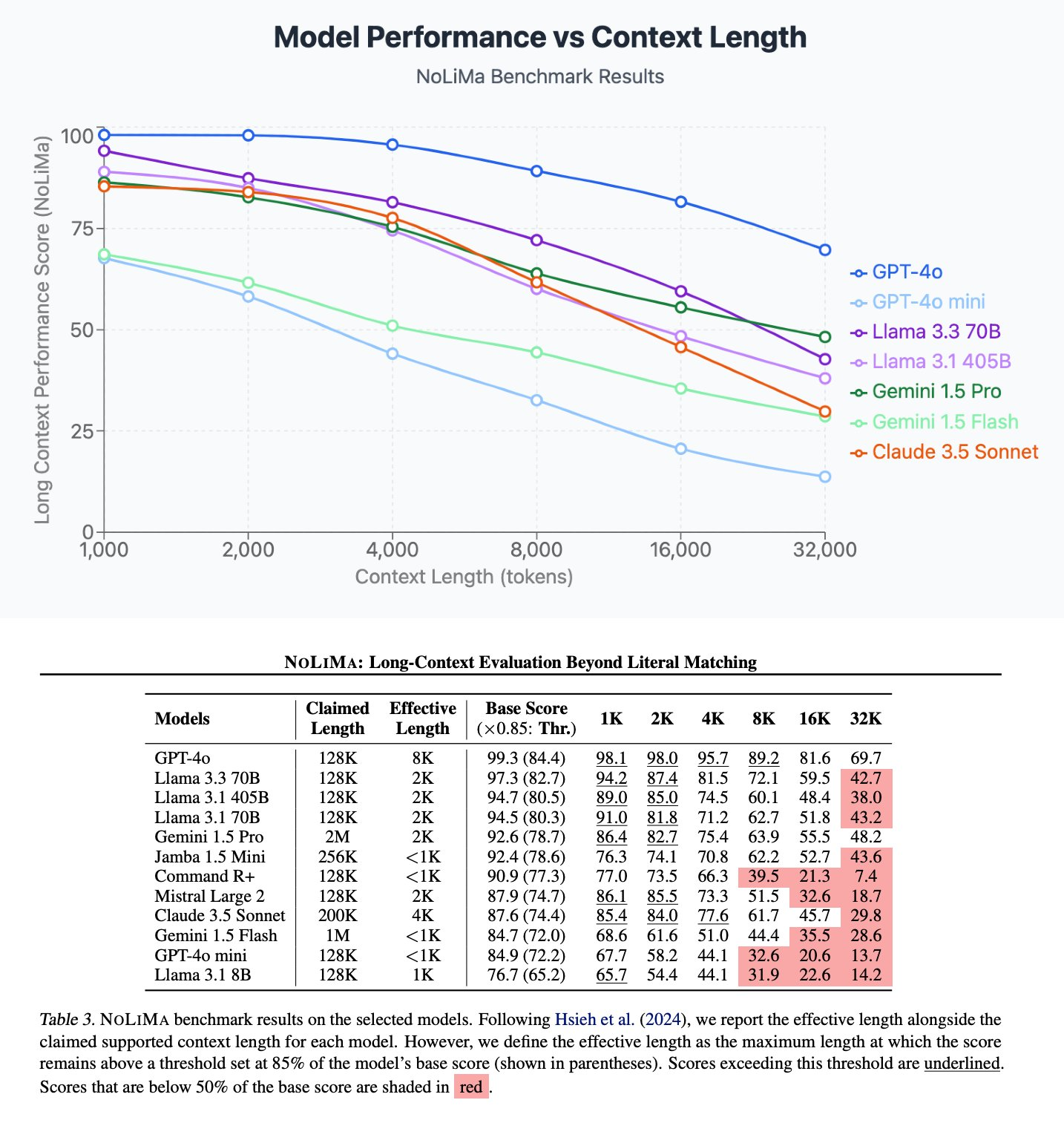
When models are asked to apply complex reasoning or infer associations over long context, performance tends to degrade more uniformly as context length increases (total context length matters).
Figure: Model performance across different context lengths in the NoLiMa benchmark. Source: Modarressi et al. (2025). "NoLiMa: Long-Context Evaluation Beyond Literal Matching." arXiv:2502.05167 [cs.CL]. Available at https://arxiv.org/abs/2502.05167.
This research is consistent with my anecdotal experience.
As I write this, I believe any task requiring an LLM to process more than 20 total pages of text at a time is a non-starter for the vast majority of legal work.
Human lawyers know they have to carefully read every clause. AI might overlook crucial indemnification exceptions or notice requirements buried in middle sections (or not at all, if asked for analysis).
The practical implication is that if you feed a due diligence report or complex contract into an out-of-the box LLM and ask for a summary or analysis, you can’t automatically assume it comprehensively processed the entire document. A coherent response doesn’t guarantee it caught everything important.
But hold fast, dear reader. There are (in my view) very effective tools we can use to work with this limitation.
If your task needs more than 20 total pages of context, divide it into smaller steps that need less background
Consolidate background into structured context that omits information irrelevant to the task
Structure your questions to explicitly direct the model's attention to specific sections. Prompt engineering can have outsized effects on how LLMs interface with context. A well-crafted prompt that directs attention to specific elements can dramatically improve performance with the same underlying model.
Use orchestrated workflows to divide both context AND tasks into manageable chunks (this is why SLI’s Barri and Sam LIAs handle different stages of contract review)
Master of None: Multi-Task Processing Issues
LLMs can handle a very wide variety of tasks (in some cases better than we can), but perform best when focusing on one thing at a time.
When asked to manage multiple complex tasks simultaneously (meaning the model needs to switch between different kinds of objectives within the same prompt), their performance degrades noticeably.
For example, asking an LLM to “analyze this contract and explain the key legal risks, then draft alternative language for sections 3.4 and 7.2 based on our playbook” will likely yield worse results than breaking these into separate, focused requests for (A) a playbook-based prompt, (B) analysis, and (C) drafting.

Research has documented this “task interference” effect. The model's internal state carries over signals from one task that bias or confuse its approach to subsequent tasks.
Figure: illustrative example of a task-switch which results in an incorrect response. Source: Gupta et al. (2024). "LLM Task Interference: An Initial Study on the Impact of Task-Switch in Conversational History." arXiv:2402.18216v2 [cs.CL]. Available at https://arxiv.org/html/2402.18216v2.
My early attempts to create autonomous “do it all” assistants for internal contract review often resulted in garbled or incomplete analysis. The model would seem to start strong on analysis, then lose focus when transitioning to drafting alternative language, sometimes completely forgetting about sections it needed to address.
Breaking complex legal tasks into smaller steps managed by separate prompts or models can dramatically improve accuracy and consistency. I think this is one of many reasons the industry has shifted toward orchestrated agentic workflows using multiple specialized models or steps, rather than one mega-model handling everything.
But worry not, dear reader. While we wait for the future we can:
Break complex legal workflows into distinct steps with clear handoffs
Use specialized prompts optimized for specific subtasks (analysis, drafting, issue spotting)
Consider orchestration frameworks to manage multi-step processes
Maintain human oversight at transition points between different tasks
The AI Style Problem
Most people quickly learn to spot a certain visual “smell” in AI-generated content.
Text is grammatically correct, fluent, responsive, but somehow lifeless and generic. It’s sort of like a giving a gift card for Christmas. Maybe it’s fine, but I almost always feel like I can do better.
I’ve heard this called “AI slop” enough times that the term itself feels tired and vacant to me. “Syntactic Templates in Generated Text” doesn’t really capture the distaste. AI has a style problem, by whatever description.
LLMs generate text by predicting likely sequences of words, which inherently drives them toward average, middle-of-the-road language patterns. They lack the idiosyncrasies and distinctive voice that humans naturally develop.
Many human beings (myself included) are much less likely to take obviously canned AI language seriously. “AI voice” can signal a lack of care or investment.
In my experience, these writing patterns are extremely persistent, and by far the most difficult of the technical limitations to manage with prompting and context.
Sometimes things are mostly beyond our control, dear reader, but I've found that providing a detailed stylebook that gives the LLM specific guidance on voice, tone, formatting preferences, and patterns to avoid can help improve first drafts.
To add some life:
Develop a stylebook and include it as part of your structured context library (foundation data) for models that create client or business facing content
Use AI for first drafts, then refine as needed
Conclusion
These limitations represent significant challenges for legal teams adopting LLM technology, but they're mostly manageable.
We've found that thoughtfully structured data, task-specific workflows, and human oversight go a long way. The difference between disappointment and delight often comes down to how the foundation and frame of the question are built.
As model architectures and reasoning capabilities continue to evolve, some of these limitations will almost certainly diminish or disappear.
Until then, I hope highlighting these limitations helps you implement AI more thoughtfully in your own business.
If you found this useful, you might also enjoy our “Foundation Data in Action” post, where we show concrete examples of how structured data can transform LLM performance.